Este é um tutorial introdutório ao framework de descrição de recursos (RDF) e Jena, uma API Java para RDF. Ele é escrito para programadores que não estão familiarizados com RDF e que aprendem melhor através de prototipagem, ou, por outros motivos, desejam avançar rapidamente para a implementação. Familiaridade com XML e Java é assumido.
Avançar direto para a implementação, sem conhecer inicialmente o modelo de dados de RDF, levará à frustração e ao desapontamento. No entanto, estudar unicamente o modelo de dados é desgastante e muitas vezes leva a "enigmas metafísicos torturantes". É melhor, então, abordar os conceitos do modelo de dados e como usá-lo, paralelamente. Aprender um pouco o modelo de dados, e praticá-lo. Então aprender um pouco mais e praticar. A teoria leva à prática , e a prática leva à teoria. O modelo de dados é relativamente simples, então esta abordagem não exigirá muito tempo.
RDF possui uma sintaxe XML, e muitos dos que são familiarizados com XML irão pensar em RDF em termos da sintaxe do XML. Isso é um erro. RDF deve ser entendido em termos do seu modelo de dados. Os dados RDF podem ser representados em XML, mas entender a sintaxe é menos importante do que entender o modelo de dados.
Uma implementação da API JENA, incluindo o código fonte dos exemplos usados neste tutorial, podem ser baixados em
jena.apache.org/download/.
O framework de descrição de recursos (RDF) é um padrão (tecnicamente uma recomendação da W3C) para descrever recursos. Mas o que são recursos? Isso é uma questão profunda e a definição precisa ainda é um assunto de debates. Para nossos propósitos, nós podemos pensar em recursos como tudo que podemos identificar. Você é um recurso, assim como sua página pessoal, este tutorial, o número um e a grande baleia branca em Moby Dick.
Nossos exemplos neste tutorial serão sobre pessoas. Elas usam uma representação RDF de cartão de negócios (VCARDS). RDF é melhor representado como um diagrama de nós e arcos. Um simples vcard se assemelha a isto em RDF:
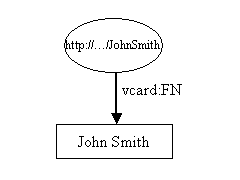
O recurso, John Smith, é exibido como uma elipse e identificado por um Identificador Uniforme de Recurso (URI)1, neste caso "http://.../JohnSmith". Se você tentar acessar o recurso usando seu navegador, não vai obter sucesso. Se você não tem familiaridade com URI's, pense neles como nomes estranhos.
Recursos possuem propriedades. Nesses exemplos, nós estamos interessados nos tipos de propriedades que apareceriam no cartão de negócios de Jonh Smith. A figura 1 mostra somente uma propriedade, o nome completo (full name) de Jonh Smith. Uma propriedade é representada por um arco, intitulado com o nome da propriedade. O nome da propriedade é também um URI, mas como os URIs são longos e incomodas, o diagrama o exibe em forma XML qname. A parte antes de ':' é chamada de prefixo namespace e representa um namespace. A parte depois de ':' é um nome local e representa o nome naquele namespace. Propriedades são normalmente representadas nesta forma de qname quando escrito como RDF XML, e isso é uma maneira prática de representá-los em diagramas e textos. No entanto, propriedades são rigorosamente representadas por um URI. A forma nsprefix:localname é um atalho para o URI do namespace concatenado com o nome local. Não há exigências de que o URI de uma propriedade resulte em algo quando acessado do navegador.
Toda propriedade possui um valor. Neste caso, o valor é uma literal, que por hora podemos pensar nelas como uma cadeia de caracteres2. Literais são exibidas em retângulos.
Jena é uma API Java que pode ser usada para pra criar e manipular grafos RDF como o apresentado no exemplo. Jena possui classes para representar grafos, recursos, propriedades e literais. As interfaces que representam recursos, propriedades e literais são chamadas de modelo e é representada pela interface Model.
O código para criar este grafo, ou modelo, é simples:
// some definitions static String personURI = "http://somewhere/JohnSmith"; static String fullName = "John Smith"; // create an empty Model Model model = ModelFactory.createDefaultModel(); // create the resource Resource johnSmith = model.createResource(personURI); // add the property johnSmith.addProperty(VCARD.FN, fullName);
Ele começa com algumas definições de constantes e então cria um Model vazio, usando o método createDefaultModel() de ModelFactory
para criar um modelo na memória. Jena possui outras implementações da interface Model, e.g. uma que usa banco de dados relacionais: esses tipos de modelo são também disponibilizados a partir de ModelFactory.
O recurso Jonh Smith é então criado, e uma propriedade é adicionada a ele. A propriedade é fornecida pela a classe "constante" VCARD, que mantém os objetos que representam todas as definições no esquema de VCARD. Jena provê classes constantes para outros esquemas bem conhecidos, bem como os próprios RDF e RDFs , Dublin Core e OWL.
O código para criar o recurso e adicionar a propriedade pode ser escrito de forma mais compacta usando um estilo cascata:
Resource johnSmith = model.createResource(personURI) .addProperty(VCARD.FN, fullName);
Os códigos desse exemplo podem ser encontrados no diretório /src-examples no pacote de distribuição do Jena como tutorial 1. Como exercício, pegue este código e modifique-o para criar um próprio VCARD para você.
Agora vamos adicionar mais detalhes ao vcard, explorando mais recursos de RDF e Jena.
No primeiro exemplo, o valor da propriedade foi um número. As propriedades RDF podem também assumir outros recursos como valor. Usando uma técnica comum em RDF, este exemplo mostra como representar diferentes partes do nome de Jonh Smith:
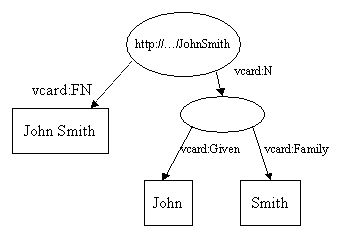
Aqui, nós adicionamos uma nova propriedade, vcard:N, para representar a estrutura do nome de Jonh Smith. Há muitas coisas interessantes sobre este modelo. Note que a propriedade vcard:N usa um recurso como seu valor. Note também que a elipse que representa a composição do nome não possui URI. Isso é conhecido como blank Node.
O código Jena para construir este exemplo é, novamente, muito simples. Primeiro algumas declarações e a criação do modelo vazio.
// some definitions String personURI = "http://somewhere/JohnSmith"; String givenName = "John"; String familyName = "Smith"; String fullName = givenName + " " + familyName; // create an empty Model Model model = ModelFactory.createDefaultModel(); // create the resource // and add the properties cascading style Resource johnSmith = model.createResource(personURI) .addProperty(VCARD.FN, fullName) .addProperty(VCARD.N, model.createResource() .addProperty(VCARD.Given, givenName) .addProperty(VCARD.Family, familyName));
Os códigos desse exemplo podem ser encontrados no diretório /src-examples no pacote de distribuição do Jena como tutorial 2.
Cada arco no modelo RDF é chamado de sentença. Cada sentença define um fato sobre o recurso. Uma sentença possui três partes:
Uma sentença é algumas vezes chamadas de tripla, por causa de suas três partes.
Um modelo RDF é representado como um conjunto de sentenças. Cada chamada a
addProperty no tutorial2 adiciona uma nova sentença. (Já que um modelo é um conjunto de sentenças, adicionar sentenças duplicadas não afeta em nada). A interface modelo de Jena define o método listStatements() que retorna um StmtIterator, um subtipo de
Iterator Java sobre todas as sentenças de um modelo.
StmtIterator possui o método nextStatement()
que retorna a próxima sentença do iterador (o mesmo que next() faz, já convertido para Statement). A interface Statement provê métodos de acesso ao sujeito, predicado e objeto de uma sentença.
Agora vamos usar essa interface para estender tutorial2 para listar todas as sentenças criadas e imprimi-las. O código completo deste exemplo pode ser encontrado em tutorial 3.
// list the statements in the Model StmtIterator iter = model.listStatements(); // print out the predicate, subject and object of each statement while (iter.hasNext()) { Statement stmt = iter.nextStatement(); // get next statement Resource subject = stmt.getSubject(); // get the subject Property predicate = stmt.getPredicate(); // get the predicate RDFNode object = stmt.getObject(); // get the object System.out.print(subject.toString()); System.out.print(" " + predicate.toString() + " "); if (object instanceof Resource) { System.out.print(object.toString()); } else { // object is a literal System.out.print(" \"" + object.toString() + "\""); } System.out.println(" ."); }
Já que o objeto de uma sentença pode ser tanto um recurso quanto uma literal, o método
getObject() retorna um objeto do tipo RDFNode, que é uma superclasse comum de ambos Resource e Literal. O objeto em si é do tipo apropriado, então o código usa instanceof para determinar qual e processá-lo de acordo.
Quando executado, o programa deve produzir a saída:
http://somewhere/JohnSmith http://www.w3.org/2001/vcard-rdf/3.0#N anon:14df86:ecc3dee17b:-7fff .
anon:14df86:ecc3dee17b:-7fff http://www.w3.org/2001/vcard-rdf/3.0#Family "Smith" .
anon:14df86:ecc3dee17b:-7fff http://www.w3.org/2001/vcard-rdf/3.0#Given "John" .
http://somewhere/JohnSmith http://www.w3.org/2001/vcard-rdf/3.0#FN "John Smith" .Agora você sabe o porquê de ser simples elaborar modelos. Se você olhar atentamente, você perceberá que cada linha consiste de três campos representando o sujeito, predicado e objeto de cada sentença. Há quatro arcos no nosso modelo, então há quatro sentenças. O "anon:14df86:ecc3dee17b:-7fff" é um identificador interno gerado pelo Jena. Não é uma URI e não deve ser confundido como tal. É simplesmente um nome interno usado pela implementação do Jena.
O W3C RDFCore Working Group definiu uma notação similar chamada N-Triples. O nome significa "notação de triplas". Nós veremos na próxima sessão que o Jena possui uma interface de escrita de N-Triples também.
Jena possui métodos para ler e escrever RDF como XML. Eles podem ser usados para armazenar o modelo RDF em um arquivo e carregá-lo novamente em outro momento.
O Tutorial 3 criou um modelo e o escreveu no formato de triplas. Tutorial 4 modifica o tutorial 3 para escrever o modelo na forma de RDF XML numa stream de saída. O código, novamente, é muito simples: model.write pode receber um OutputStream como argumento.
// now write the model in XML form to a file model.write(System.out);
A saída deve parecer com isso:
<rdf:RDF xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#' xmlns:vcard='http://www.w3.org/2001/vcard-rdf/3.0#' > <rdf:Description rdf:about='http://somewhere/JohnSmith'> <vcard:FN>John Smith</vcard:FN> <vcard:N rdf:nodeID="A0"/> </rdf:Description> <rdf:Description rdf:nodeID="A0"> <vcard:Given>John</vcard:Given> <vcard:Family>Smith</vcard:Family> </rdf:Description> </rdf:RDF>
As especificações de RDF especificam como representar RDF como XML. A sintaxe de RDF XML é bastante complexa. Recomendamos ao leitor dar uma olhada no primer sendo desenvolvido pelo RDFCore WG para uma introdução mais detalhada. Entretanto, vamos dar uma olhada rápida em como interpretar a saída acima.
RDF é normalmente encapsulada num elemento <rdf:RDF>. O elemento é opcional se houver outras maneiras de saber se aquele XML é RDF, mas normalmente ele é presente. O elemento RDF define os dois namespaces usados no documento. Há um elemento <rdf:Description> que descreve o recurso cuja URI é "http://somewhere/JohnSmith". Se o atributo rdf:about estivesse ausente, esse elemento representaria um blank node.
O elemento <vcard:FN> descreve uma propriedade do recurso. O nome da propriedade é o "FN" no namespace do vcard. RDF o converte para uma referência URI concatenando a referência URI do prefixo presente no namespace de vcard e "FN", o nome local parte do nome. Isto nos dá a referência URI " http://www.w3.org/2001/vcard-rdf/3.0#FN". O valor da propriedade é a literal "Jonh Smith".
O elemento <vcard:N> é um recurso. Neste caso, o recurso é representado por uma referência URI relativa. RDF o converte para uma referência URI absoluta concatenando com o URI base do documento.
Há um erro nesse RDF XML: ele não representa exatamente o modelo que criamos. Foi dado uma URI ao blank node do modelo. Ele não é mais um blank node portanto. A sintaxe RDF/XML não é capaz de representar todos os modelos RDF; por exemplo, ela não pode representar um blank node que é o objeto de duas sentenças. O escritor que usamos para escrever este RDF/XML não é capaz de escrever corretamente o subconjunto de modelos que podem ser escritos corretamente. Ele dá uma URI a cada blank node, tornando-o não mais blank.
Jena possui uma interface extensível que permite novos escritores para diferentes linguagens de serialização RDF. Jena possuem também um escritor RDF/XML mais sofisticado que pode ser invocado ao especificar outro argumento à chamada de método
write():
// now write the model in XML form to a file model.write(System.out, "RDF/XML-ABBREV");
Este escritor, chamado também de PrettyWriter, ganha vantagem ao usar as particularidades da sintaxe abreviada de RDF/XML ao criar um modelo mais compacto. Ele também é capaz de preservar os blank nodes onde é possível. Entretanto, não é recomendável para escrever modelos muito grandes, já que sua desempenho deixa a desejar. Para escrever grandes arquivos e preservar os blank nodes, escreva no formato de N-Triplas:
// now write the model in XML form to a file model.write(System.out, "N-TRIPLE");
Isso produzirá uma saída similar à do tutorial 3, que está em conformidade com a especificação de N-Triplas.
Tutorial 5 demonstra a leitura num modelo de sentenças gravadas num RDF XML. Com este tutorial, nós teremos criado uma pequena base de dados de vcards na forma RDF/XML. O código a seguir fará leitura e escrita. Note que para esta aplicação rodar, o arquivo de entrada precisa estar no diretório da aplicação.
// create an empty model Model model = ModelFactory.createDefaultModel(); // use the FileManager to find the input file InputStream in = FileManager.get().open( inputFileName ); if (in == null) { throw new IllegalArgumentException( "File: " + inputFileName + " not found"); } // read the RDF/XML file model.read(in, null); // write it to standard out model.write(System.out);
O segundo argumento da chamada de método read() é a URI que será usada para resolver URIs relativas. Como não há referências URI relativas no arquivo de teste, ele pode ser vazio. Quando executado, tutorial 5 produzirá uma saída XML como esta:
<rdf:RDF xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#' xmlns:vcard='http://www.w3.org/2001/vcard-rdf/3.0#' > <rdf:Description rdf:nodeID="A0"> <vcard:Family>Smith</vcard:Family> <vcard:Given>John</vcard:Given> </rdf:Description> <rdf:Description rdf:about='http://somewhere/JohnSmith/'> <vcard:FN>John Smith</vcard:FN> <vcard:N rdf:nodeID="A0"/> </rdf:Description> <rdf:Description rdf:about='http://somewhere/SarahJones/'> <vcard:FN>Sarah Jones</vcard:FN> <vcard:N rdf:nodeID="A1"/> </rdf:Description> <rdf:Description rdf:about='http://somewhere/MattJones/'> <vcard:FN>Matt Jones</vcard:FN> <vcard:N rdf:nodeID="A2"/> </rdf:Description> <rdf:Description rdf:nodeID="A3"> <vcard:Family>Smith</vcard:Family> <vcard:Given>Rebecca</vcard:Given> </rdf:Description> <rdf:Description rdf:nodeID="A1"> <vcard:Family>Jones</vcard:Family> <vcard:Given>Sarah</vcard:Given> </rdf:Description> <rdf:Description rdf:nodeID="A2"> <vcard:Family>Jones</vcard:Family> <vcard:Given>Matthew</vcard:Given> </rdf:Description> <rdf:Description rdf:about='http://somewhere/RebeccaSmith/'> <vcard:FN>Becky Smith</vcard:FN> <vcard:N rdf:nodeID="A3"/> </rdf:Description> </rdf:RDF>
Na sessão anterior, nós vimos que a saída XML declarou um prefixo namespace
vcard e o usou para abreviar URIs. Enquanto que RDF usa somente URIs completas, e não sua forma encurtada, Jena provê formas de controlar namespaces usados na saída com seu mapeamento de prefixos. Aqui vai um exemplo simples.
Model m = ModelFactory.createDefaultModel(); String nsA = "http://somewhere/else#"; String nsB = "http://nowhere/else#"; Resource root = m.createResource( nsA + "root" ); Property P = m.createProperty( nsA + "P" ); Property Q = m.createProperty( nsB + "Q" ); Resource x = m.createResource( nsA + "x" ); Resource y = m.createResource( nsA + "y" ); Resource z = m.createResource( nsA + "z" ); m.add( root, P, x ).add( root, P, y ).add( y, Q, z ); System.out.println( "# -- no special prefixes defined" ); m.write( System.out ); System.out.println( "# -- nsA defined" ); m.setNsPrefix( "nsA", nsA ); m.write( System.out ); System.out.println( "# -- nsA and cat defined" ); m.setNsPrefix( "cat", nsB ); m.write( System.out );
A saída deste fragmento são três blocos de RDF/XML, com três diferentes mapeamentos de prefixos. Primeiro o padrão, sem prefixos diferentes dos padrões:
# -- no special prefixes defined <rdf:RDF xmlns:j.0="http://nowhere/else#" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:j.1="http://somewhere/else#" > <rdf:Description rdf:about="http://somewhere/else#root"> <j.1:P rdf:resource="http://somewhere/else#x"/> <j.1:P rdf:resource="http://somewhere/else#y"/> </rdf:Description> <rdf:Description rdf:about="http://somewhere/else#y"> <j.0:Q rdf:resource="http://somewhere/else#z"/> </rdf:Description> </rdf:RDF>
Nós vimos que o namespace rdf é declarado automaticamente, já que são requeridos para tags como <RDF:rdf> e <rdf:resource>. Declarações de namespace são também necessárias para o uso das duas propriedades P e Q, mas já que seus namespaces não foram introduzidos no modelo, eles recebem nomes namespaces inventados j.0 e j.1.
O método setNsPrefix(String prefix, String URI)
declara que o namespace da URI deve ser abreviado por prefixos. Jena requer que o prefixo seja um namespace XML correto, e que o URI termine com um caractere sem-nome. O escritor RDF/XML transformará essas declarações de prefixos em declarações de namespaces XML e as usará nas suas saídas:
O outro namespace ainda recebe o nome criado automaticamente, mas o nome nsA é agora usado nas tags de propriedades. Não há necessidade de que o nome do prefixo tenha alguma relação com as variáveis do código Jena:# -- nsA defined <rdf:RDF xmlns:j.0="http://nowhere/else#" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:nsA="http://somewhere/else#" > <rdf:Description rdf:about="http://somewhere/else#root"> <nsA:P rdf:resource="http://somewhere/else#x"/> <nsA:P rdf:resource="http://somewhere/else#y"/> </rdf:Description> <rdf:Description rdf:about="http://somewhere/else#y"> <j.0:Q rdf:resource="http://somewhere/else#z"/> </rdf:Description> </rdf:RDF>
Ambos os prefixos são usados na saída, e não houve a necessidade de prefixos gerados automaticamente.# -- nsA and cat defined <rdf:RDF xmlns:cat="http://nowhere/else#" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:nsA="http://somewhere/else#" > <rdf:Description rdf:about="http://somewhere/else#root"> <nsA:P rdf:resource="http://somewhere/else#x"/> <nsA:P rdf:resource="http://somewhere/else#y"/> </rdf:Description> <rdf:Description rdf:about="http://somewhere/else#y"> <cat:Q rdf:resource="http://somewhere/else#z"/> </rdf:Description> </rdf:RDF>
setNsPrefix, Jena vai lembrar-se dos prefixos que foram usados na entrada para model.read().
Pegue a saída produzida pelo fragmento anterior e cole-o dentro de algum arquivo, com a URL file:/tmp/fragment.rdf say. E execute o código:
Você verá que os prefixos da entrada são preservados na saída. Todos os prefixos são escritos, mesmo se eles não forem usados em lugar algum. Você pode remover um prefixo comModel m2 = ModelFactory.createDefaultModel(); m2.read( "file:/tmp/fragment.rdf" ); m2.write( System.out );
removeNsPrefix(String prefix) se você não o quiser na saída.
Como N-Triplas não possuem nenhuma forma reduzida de escrever URIs, não há prefixos nem na entrada nem na saída. A notação N3, também suportada pelo Jena, possui nomes prefixados reduzidos, e grava-os na entrada e usa-os na saída.
Jena possui outras operações sobre mapeamento de prefixos de um modelo, como umMap de Java extraído a partir dos mapeamentos existentes, ou a adição de um grupo inteiro de mapeamentos de uma só vez; olhe a documentação de PrefixMapping para mais detalhes.
Jena é uma API JAVA para aplicações de web semântica. O pacote RDF chave para o desenvolvedor é
com.hp.hpl.jena.rdf.model. A API tem sido definida em termos de interfaces, logo o código da aplicação pode trabalhar com diferentes implementações sem causar mudanças. Esse pacote contém interfaces para representar modelos, recursos, propriedades, literais, sentenças e todos os outros conceitos chaves de RDF, e um ModelFactory para criação de modelos. Portanto, o código da aplicação permanece independente da implementação, o melhor é usar interfaces onde for possível e não implementações específicas de classes.
O pacote com.hp.hpl.jena.tutorial contém o código fonte funcional de todos os exemplos usados neste tutorial.
Os pacotes com.hp.hpl.jena...impl contêm a implementação de classes que podem ser comuns a várias implementações. Por exemplo, eles definem as classes ResourceImpl,
PropertyImpl, e LiteralImpl que podem ser usadas diretamente ou então herdadas por diferentes implementações. As aplicações devem raramente usar essas classes diretamente. Por exemplo, em vez de criar um nova instância de ResourceImpl, é melhor usar o método createResource do modelo que estiver sendo usado. Desta forma, se a implementação do modelo usar uma implementação otimizada de Resource, então não serão necessárias conversões entre os dois tipos.
Até agora, este tutorial mostrou como criar, ler e escrever modelos RDF. Chegou o momento de mostrar como acessar as informações mantidas num modelo.
Dada a URI de um recurso, o objeto do recurso pode ser recuperado de um modelo usando o método Model.getResource(String uri). Este método é definido para retornar um objeto Resource se ele existir no modelo, ou, caso contrário, criar um novo. Por exemplo, para recuperar o recurso Adam Smith do modelo lido a partir do arquivo no tutorial 5:
// retrieve the John Smith vcard resource from the model Resource vcard = model.getResource(johnSmithURI);
A interface Resource define numerosos métodos para acessar as propriedades de um recurso. O método Resource.getProperty(Property p) acessa uma propriedade do recurso. Este método não segue a convenção usual de Java de acesso já que o tipo do objeto retorna é Statement, e não Property como era de se esperar. Retornando toda a sentença permite à aplicação acessar o valor da propriedade usando um de seus métodos de acesso que retornam o objeto da sentença. Por exemplo, para recuperar o recurso que é o valor da propriedade vcard:N
// retrieve the value of the N property Resource name = (Resource) vcard.getProperty(VCARD.N) .getObject();
De modo geral, o objeto de uma sentença pode ser um recurso ou uma literal, então a aplicação, sabendo que o valor precisar ser um recurso, faz o cast do objeto retornado. Uma das coisas que Jena tenta fazer é fornecer tipos específicos de métodos, então a aplicação não tem que fazer cast, e checagem de tipos pode ser feita em tempo de compilação. O fragmento de código acima poderia ser mais convenientemente escrito assim:
// retrieve the value of the FN property Resource name = vcard.getProperty(VCARD.N) .getResource();
Similarmente, o valor literal de uma propriedade pode ser recuperado:
// retrieve the given name property String fullName = vcard.getProperty(VCARD.FN) .getString();
Neste exemplo, o recurso vcard possui somente as propriedades vcard:FN e vcard:N. RDF permite a um recurso repetir uma propriedade; por exemplo, Adam pode ter mais de um apelido. Vamos dar dois apelidos a ele:
// add two nickname properties to vcard vcard.addProperty(VCARD.NICKNAME, "Smithy") .addProperty(VCARD.NICKNAME, "Adman");
Como notado anteriormente, Jena representa um modelo RDF como um conjunto de sentenças, então, adicionar uma sentença com um sujeito, predicado e objeto igual a um já existente não terá efeito. Jena não define qual do dois apelidos será retornado. O resultado da chamada a vcard.getProperty(VCARD.NICKNAME) é indeterminado. Jena vai retornar um dos valores, mas não há garantia nem mesmo de que duas chamadas consecutivas irá retornar o mesmo valor.
Se for possível que uma propriedade ocorra mais de uma vez, então o método Resource.listProperties(Property p) pode ser usado para retornar um iterador para lista-las. Este método retorna um iterador que retorna objetos do tipo Statement. Nós podemos listar os apelidos assim:
// set up the output System.out.println("The nicknames of \"" + fullName + "\" are:"); // list the nicknames StmtIterator iter = vcard.listProperties(VCARD.NICKNAME); while (iter.hasNext()) { System.out.println(" " + iter.nextStatement() .getObject() .toString()); }
Esse código pode ser encontrado em tutorial 6. O iterador iter reproduz todas as sentenças com sujeito vcard e predicado VCARD.NICKNAME, então, iterar sobre ele permite recuperar cada sentença usando
nextStatement(), pegar o campo do objeto, e convertê-lo para string. O código produz a seguinte saída quando executado:
The nicknames of "John Smith" are: Smithy Adman
Todas as propriedades de um recurso podem ser listadas usando o método
listProperties() sem argumentos.
A sessão anterior mostrou como navegar um modelo a partir de um recurso com uma URI conhecida. Essa sessão mostrará como fazer buscas em um modelo. O núcleo da API Jena suporta um limitada primitiva de consulta. As consultas mais poderosas de RDQL são descritas em outros lugares.
O método Model.listStatements(), que lista todos as sentenças de um modelo, é talvez a forma mais crua de se consultar um modelo. Este uso não é recomendado em modelos muito grandes.
Model.listSubjects() é similar, mas retorna um iterador sobre todos os recursos que possuem propriedades, ie são sujeitos de alguma sentença.
Model.listSubjectsWithProperty(Property p, RDFNode
o) retornará um iterador sobre todos os recursos com propriedade p de valor o. Se nós assumirmos que somente recursos vcard terão a propriedade vcard:FN e que, em nossos dados, todos esses recursos têm essa propriedade, então podemos encontrar todos os vCards assim:
// list vcards ResIterator iter = model.listSubjectsWithProperty(VCARD.FN); while (iter.hasNext()) { Resource r = iter.nextResource(); ... }
Todos esses métodos de consulta são acuçar sintático sobre o método primitivo de consulta model.listStatements(Selector s). Esse método retorna um iterador sobre todas as sentenças no modelo 'selecionado' por s. A interface de selector foi feita para ser extensível, mas por hora, só há uma implementação dela, a classe SimpleSelector do pacote com.hp.hpl.jena.rdf.model. Usar SimpleSelector é uma das raras ocasiões em Jena onde é necessário usar uma classe especifica em vez de uma interface. O construtor de SimpleSelector recebe três argumentos:
Selector selector = new SimpleSelector(subject, predicate, object)
Esse selector vai selecionar todas as sentenças em que o sujeito casa com
subject, um predicado que casa com predicate e um objeto que casa com object. Se null é passado para algum dos argumentos, ele vai casar com qualquer coisa, caso contrário, ele vai casar com os recursos ou literais correspondentes. (Dois recursos são iguais se eles possuem o mesmo URI ou são o mesmo blank node; dois literais são iguais se todos os seus componentes forem iguais.) Assim:
Selector selector = new SimpleSelector(null, null, null);
vai selecionar todas as sentenças do modelo.
Selector selector = new SimpleSelector(null, VCARD.FN, null);
vai selecionar todas as sentenças com o predicado VCARD.FN, independente do sujeito ou objeto. Como um atalho especial,
listStatements( S, P, O )
listStatements( new SimpleSelector( S, P, O ) )
O código a seguir, que pode ser encontrado em tutorial 7 que lista os nomes completos de todos os vcards do banco de dados.
// select all the resources with a VCARD.FN property ResIterator iter = model.listSubjectsWithProperty(VCARD.FN); if (iter.hasNext()) { System.out.println("The database contains vcards for:"); while (iter.hasNext()) { System.out.println(" " + iter.nextStatement() .getProperty(VCARD.FN) .getString()); } } else { System.out.println("No vcards were found in the database"); }
Isso deve produzir uma saída similar a:
The database contains vcards for: Sarah Jones John Smith Matt Jones Becky Smith
Seu próximo exercício é modificar o código para usar SimpleSelector
em vez de listSubjectsWithProperty.
Vamos ver como implementar um controle mais refinado sobre as sentenças selecionadas.
SimpleSelector pode ser herdado ter seus selects modificado para mais filtragens:
// select all the resources with a VCARD.FN property // whose value ends with "Smith" StmtIterator iter = model.listStatements( new SimpleSelector(null, VCARD.FN, (RDFNode) null) { public boolean selects(Statement s) {return s.getString().endsWith("Smith");} });
Esse código usa uma técnica elegante de Java para sobrescrever a definição de um método quando criamos uma instância da classe. Aqui, o método selects(...) garante que o nome completo termine com “Smith”. É importante notar que a filtragem baseada nos argumentos sujeito, predicado e objeto tem lugar antes que o método selects(...) seja chamado, então esse teste extra só será aplicado para casar sentenças.
O código completo pode ser encontrado no tutorial 8 e produz uma saída igual a:
The database contains vcards for: John Smith Becky Smith
Você pode imaginar que:
// do all filtering in the selects method StmtIterator iter = model.listStatements( new SimpleSelector(null, null, (RDFNode) null) { public boolean selects(Statement s) { return (subject == null || s.getSubject().equals(subject)) && (predicate == null || s.getPredicate().equals(predicate)) && (object == null || s.getObject().equals(object)) } } });
é equivalente a:
StmtIterator iter = model.listStatements(new SimpleSelector(subject, predicate, object)
Embora possam ser funcionalmente equivalentes, a primeira forma vai listar todas as sentenças do modelo e testar cada uma individualmente, a segunda forma permite índices mantidos pela implementação para melhor a perfomance. Tente isso em modelos grandes e veja você mesmo, mas prepare uma chícara de café antes.
Jena provê três operações para manipular modelos. Elas são operações comuns de conjunto: unão, intersecção e diferença.
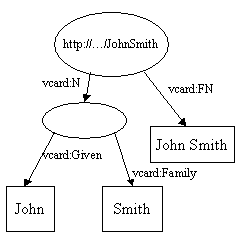
A união de dois modelos é a união do conjunto de sentenças que representa cada modelo. Esta é uma das operações chaves que RDF suporta. Isso permite que fontes de dados discrepantes sejam juntadas. Considere o seguintes modelos:
 and
and
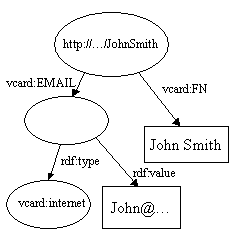
Quando eles são juntados, os dois nós http://...JohnSmith são unidos em um, e o arco vcard:FN duplicado é descartado para produzir:
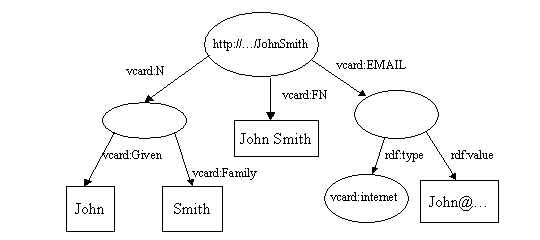
Vamos ver o código (o código completo está em tutorial 9) e ver o que acontece.
// read the RDF/XML files model1.read(new InputStreamReader(in1), ""); model2.read(new InputStreamReader(in2), ""); // merge the Models Model model = model1.union(model2); // print the Model as RDF/XML model.write(system.out, "RDF/XML-ABBREV");
A saída produzida pelo PrettyWriter se assemelha a:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:vcard="http://www.w3.org/2001/vcard-rdf/3.0#"> <rdf:Description rdf:about="http://somewhere/JohnSmith/"> <vcard:EMAIL> <vcard:internet> <rdf:value>John@somewhere.com</rdf:value> </vcard:internet> </vcard:EMAIL> <vcard:N rdf:parseType="Resource"> <vcard:Given>John</vcard:Given> <vcard:Family>Smith</vcard:Family> </vcard:N> <vcard:FN>John Smith</vcard:FN> </rdf:Description> </rdf:RDF>
Mesmo que você não seja familiarizado com os detalhes da sintaxe RDF/XML, deve ser relativamente claro que os modelos foram unidos como esperado A interseção e a diferença de modelos podem ser computados de maneira semelhante, usando os métodos .intersection(Model) e
.difference(Model); veja a documentação de
difference
e
intersection
para mais detalhes.
RDF defina um tipo especial de recursos para representar coleções de coisas. Esses recursos são chamados de containers. Os membros de um container podem ser tanto literais quanto recursos. Há três tipos de containers:
Um container é representado por um recurso. Esse recurso terá uma propriedade rdf:type cujo valor deve ser rdf:Bag, rdf:Alt, rdf:Seq, ou uma subclasse deles, dependendo do tipo do container. O primeiro membro do container é o valor da propriedade rdf:_1 do container; o segundo membro é o valor da propriedade rdf:_2 e assim por diante. As propriedades rdf:_nnn são conhecidas como propriedades ordinais.
Por exemplo, o modelo para uma bag simples contendo os vcards dos Smith pode se assemelhar a:
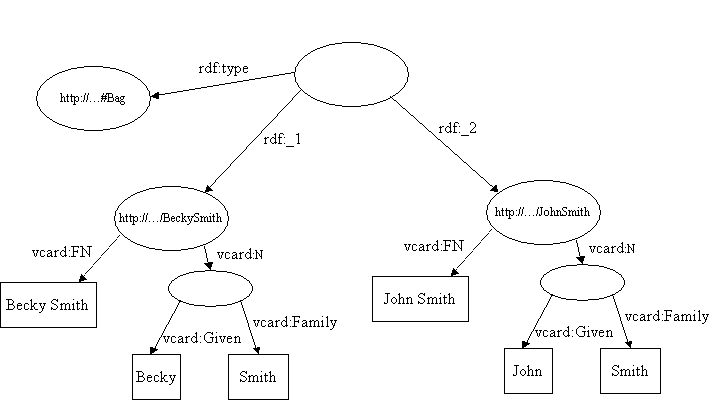
Embora os membros do bag serem representados pelas propriedades rdf:_1, rdf:_2 etc. a ordem das propriedades é insignificante. Nós poderíamos trocar os valores das propriedades rdf_1 e rdf_2 o resultado do modelo representaria a mesma informação.
ALTs representam alternativas. Por exemplo, vamos supor um recurso representando um software. Ele poderia ter uma propriedade indicando onde ele foi obtido. O valor dessa propriedade pode ser uma coleção ALT contendo vários sites de onde ele poderia ser baixado. ALTs são desordenados a menos que a propriedade rdf:_1 tenha significado especial. Ela representa a escolha padrão.
Embora os containers sejam manipulados como recursos e propriedades, Jena têm interfaces e implementações de classes explicitas para manipulá-los. Não é uma boa ideia ter um objeto manipulando um container e ao mesmo tempo modificando o estado do container usando métodos de mais baixo nível.
Vamos modificar o tutorial 8 para criar essa bag:
// create a bag Bag smiths = model.createBag(); // select all the resources with a VCARD.FN property // whose value ends with "Smith" StmtIterator iter = model.listStatements( new SimpleSelector(null, VCARD.FN, (RDFNode) null) { public boolean selects(Statement s) { return s.getString().endsWith("Smith"); } }); // add the Smith's to the bag while (iter.hasNext()) { smiths.add(iter.nextStatement().getSubject()); }
Se nós imprimirmos esse modelo, vamos obter algo do tipo:
<rdf:RDF xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#' xmlns:vcard='http://www.w3.org/2001/vcard-rdf/3.0#' > ... <rdf:Description rdf:nodeID="A3"> <rdf:type rdf:resource='http://www.w3.org/1999/02/22-rdf-syntax-ns#Bag'/> <rdf:_1 rdf:resource='http://somewhere/JohnSmith/'/> <rdf:_2 rdf:resource='http://somewhere/RebeccaSmith/'/> </rdf:Description> </rdf:RDF>
que representa o recurso Bag.
A interface do container fornece um iterador para listar o conteúdo do container:
// print out the members of the bag NodeIterator iter2 = smiths.iterator(); if (iter2.hasNext()) { System.out.println("The bag contains:"); while (iter2.hasNext()) { System.out.println(" " + ((Resource) iter2.next()) .getProperty(VCARD.FN) .getString()); } } else { System.out.println("The bag is empty"); }
que produz a seguinte saída:
The bag contains: John Smith Becky Smith
O código executável pode ser encontrado em tutorial 10, que coloca esses fragmentos de código juntos num exemplo completo.
As classes de Jena oferecem métodos para manipular containers, incluindo adição de novos membros, inserção de novos membros no meio de um container e a remoção de membros existentes. As classes de container Jena atualmente garantem que a lista ordenada de propriedades usadas começam com rdf:_1 e é contíguo. O RDFCore WG relaxou essa regra, permitindo uma representação parcial dos containers. Isso, portanto, é uma área de Jena que pode ser mudada no futuro.
Literais RDF não são apenas strings. Literais devem ter uma tag para indicar a linguagem da literal. O diálogo de uma literal em Inglês é considerado diferente de um diálogo de uma literal em Francês. Esse comportamento estranho é um artefato da sintaxe RDF/XML original.
Há na realidade dois tipos de Literais. Em uma delas, o componente string é somente isso, uma string ordinária. Na outra, o componente string é esperado que fosse um bem balanceado fragmento de XML. Quando um modelo RDF é escrito como RDF/XML, uma construção especial usando um atributo parseType='Literal' é usado para representar isso.
Em Jena, esses atributos de uma literal podem ser setados quando a literal é construída, e.g. no tutorial 11:
// create the resource Resource r = model.createResource(); // add the property r.addProperty(RDFS.label, model.createLiteral("chat", "en")) .addProperty(RDFS.label, model.createLiteral("chat", "fr")) .addProperty(RDFS.label, model.createLiteral("<em>chat</em>", true)); // write out the Model model.write(system.out);
produz
<rdf:RDF xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#' xmlns:rdfs='http://www.w3.org/2000/01/rdf-schema#' > <rdf:Description rdf:nodeID="A0"> <rdfs:label xml:lang='en'>chat</rdfs:label> <rdfs:label xml:lang='fr'>chat</rdfs:label> <rdfs:label rdf:parseType='Literal'><em>chat</em></rdfs:label> </rdf:Description> </rdf:RDF>
Para que duas literais sejam consideradas iguais, elas devem ser ambas literais XML ou ambas literais simples. Em adição a isso, ambas não devem possuir tag de linguagem, ou se as tags de linguagem estiverem presentes, elas devem ser iguais. Para simples literais strings, elas devem ser iguais. Literais XML têm duas noções de igualdade. A noção simples é que as condições anteriores são verdade e as strings também são iguais. A outra noção é de que elas podem ser iguais se a canonização das strings forem iguais.
As interfaces de Jena também suportam literais tipadas. A maneira antiga (mostrada abaixo) trata literais tipadas como atalhos para strings: valores tipados são convertidos por Java em strings, e essas strings são armazenadas no modelo. Por exemplo, tente (observando que para literais simples, nós podemos omitir a chamada code>model.createLiteral(...)):
// create the resource Resource r = model.createResource(); // add the property r.addProperty(RDFS.label, "11") .addProperty(RDFS.label, 11); // write out the Model model.write(system.out, "N-TRIPLE");
A saída produzida é:
_:A... <http://www.w3.org/2000/01/rdf-schema#label> "11" .
Já que ambas as literais são apenas a string “’11”, então somente uma sentença é adicionada
O RDFCore WG definiu mecanismos para suportar datatypes em RDF. Jena os suporta usando mecanismos de literais tipadas; isso não é discutido neste tutorial.